
Despite the availability of fast processors with dedicated floating-point support, we still see many projects generating fixed-point code from Simulink. The reason for this is not only the resource usage, but also the more transparent and predictable mathematical behavior. You can read more about this in our previous articles “What you should know about fixed-point” and “What you should know about floating-point”.
Assuming that we want to generate fixed-point production code from a Simulink model, there are basically two choices:
- directly create a Simulink model with fixed-point types or
- create a floating-point model first
The first option might seem natural, but starting with a floating-point model can have several advantages. Let’s try to look at it from three perspectives:
1. Development
In the automotive industry, applications in general and software in particular is getting more complex. With this growing complexity, we see many projects which separate the role of the function developer from the role of the software developer. The function developer might be an engineer with detailed domain knowledge (e.g. about the powertrain) while the software developer has the knowledge about the production code and the implementation details. In such a setting, it makes a lot of sense to allow the function developer to work in a somehow ideal mathematical world of float double types in Simulink, where he can focus on the actual algorithms, maybe do some rapid prototyping, and doesn’t need to think about implementation details like bit sizes or scalings. This would happen in a second step, where the software developer will configure and parametrize the code generator and in particular take care of the fixed-point data types and the scaling.
2. Testing and Debugging
When test cases fail, we need to start a debugging to find the root cause. But if we directly implement everything in fixed-point the question is: Does the failed test case come from a problem with the algorithm or a problem with the scalings and resolutions of the variables.
If we create a floating-point model first, we can be sure that any errors found during requirements-based testing on model level (MIL) result from the algorithm itself.
In a second step, we can perform a Back-to-Back Test between model (MIL) and code (SIL/PIL) with suitable tolerances. Any deviations which occur in this second step would be caused by the scaling.
3. Reuse
Especially for larger projects, it is recommended to create a hierarchical software architecture where the actual software units are limited in their size. This is also directly mentioned in the ISO 26262 specification, which asks for “Appropriate hierarchical structure of the software components” and “Restricted size and complexity of software components”. We already talked about this topic in context of Model-based Development in our blog article “Modular Model-based Software Architecture for Efficient Unit and Integration Test”.
Another positive effect of small software units is the potential to reuse them in different projects and/or on different target platforms. But this might require an adaption of the implementation data types. With a “master” Simulink model using FLP data types, we have the flexibility to generate different variants of the production code with either FLP data types or 8/16/32-bit FXP types. Each variant would require it’s dedicated Back-to-Back Test between model and code, but other test activities like Requirements-based Testing would only happen once at the model level.
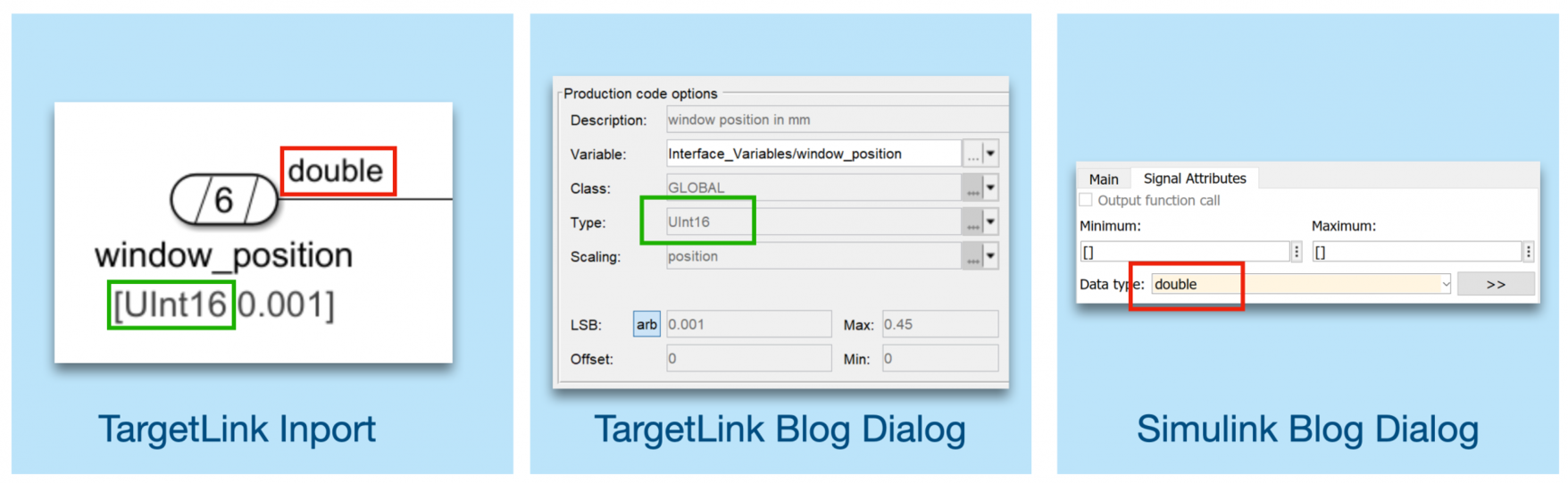
Conclusion
Generating fixed-point code from a floating-point model can bring several benefits to the different stakeholders in a Model-based Development process. Function developers and software developers can efficiently focus on different aspects of the process. Test engineers can independently deal with different error sources. And last but not least, a model which is more independent from the actual implementation is more reusable within different projects and/or on different targets.
P.S.: Even in a floating-point model, it makes sense to use boolean/integer/enum types for the variables which do not represent a continous range of values.

