The automatic test case generation has always been a controversial topic. While some people dream about stopping any manual test activities others say that test generation is not allowed.
But who is right?

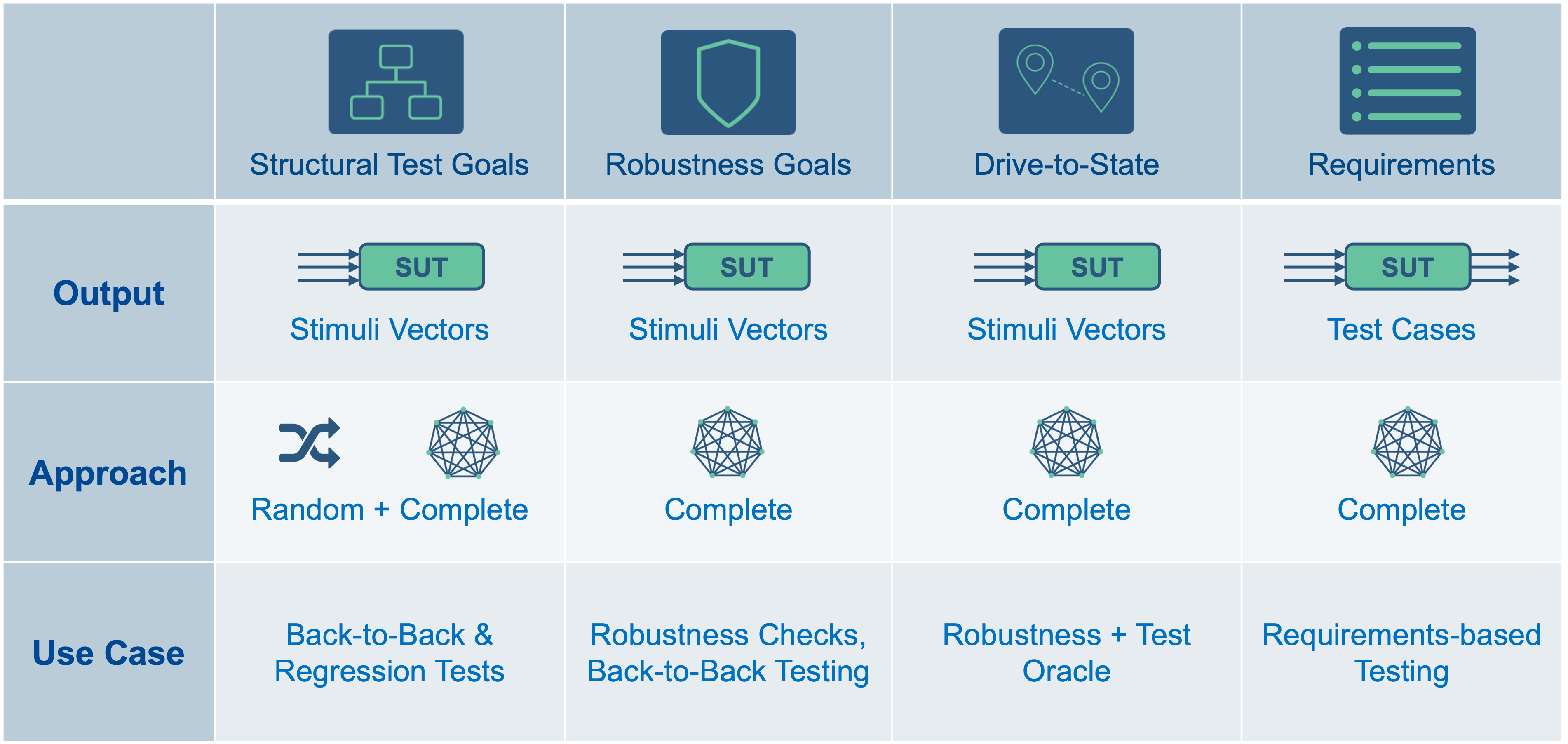
Test Goals for automatic test case generation
Let’s have a quick look at the possible test goals for which we can generate test cases.

Structural coverage goals come from the model or code directly. This includes, but is not limited to, Statement, Decision and MD/DC coverage. As a rule, it is intended that these test goals are covered by test cases.
If those goals cannot be covered, it could be useful to have a closer look. It might be possible to have dead code which should be avoided in your production code.

Robustness coverage goals are also derived from the code and include for instance, Division-by-Zeros and critical Down Casts. In contrast to the structural coverage goals, this condition is undesirable because it could have a critical impact on the robustness of your system.

Drive-To-State goals are user defined and represent specific states of the system under test (SUT). This determines confirmation of whether or not certain states can be reached, and what input combinations would create those states. This is also useful for monitoring a critical state that should not be covered by any input combination.

Requirements-based test cases can also be automatically generated by your computer, and are based on a machine-readable representation of the requirement previously created by the user. This is also called a “Formal Requirement” because it has a clearly defined syntax and semantics, and also describes timing constraints if applicable.
I think that up to this point everyone agrees. However, it is not only important to look at the possible test goals for automatic test case generation but also to see what test data is generated based on the different test goals.

For the Structural, Robustness, and Drive-To-State test goals the word test case is a bit misleading and maybe one reason this can lead to a controversial discussion. So, we prefer the term “stimuli vector,” because the generated test data will only contain input data. This includes inputs that can change from step to step and parameters/calibrations that remain stable in one stimuli vector or test case.
The stimuli vectors only show a possible input sequence that covers a certain test goal, but – and this is very important to understand – do not contain any output data. Because a stimuli vector is generated based on a model or the code, it cannot generate expected values for the output signals. The generated expectation values would be a self-fulfilling prophecy and would also have no significance at all as to whether the system is behaving correctly. A system cannot verify by itself whether it is behaving correctly.
Critics of automatic test case generation argue that this is the reason structural „test cases“ are meaningless. However, there are useful use cases for stimuli vectors that we will look at in a moment.

For the case of a formal requirement the user has defined the expected output behavior in a machine-readable representation, allowing the computer to generate not only input but also expected output data. Although the test case is also generated based on a model or code, the computer has additional information coming from the formal requirement. This is basically the same as a human tester who takes the requirement and creates a test case based on the interface of the system under test.
Approaches to generate test data
Having established what kind of goals test cases can be generated for and what kind of test data (stimuli vectors or test cases) can be generated based on the different test goals, we can have a look at available technologies to generate these test cases. Basically, there are two technologies available on the market.
Random

The most common approach for automatic test case generation is to generate random input data and to check what test goals are covered based on the generated data. This is done on an instrumented version of a model or code. To make this approach more efficient, a heuristic can control in what ranges random data is generated.
The advantage of this approach is that it is quite fast and it can be easily implemented. However, depending on the concrete implementation, you might get many redundancies and probably very long stimuli vectors. In addition, it can only show that a certain test goal can be covered. However, this method is unable to determine if a test goal like a Division-by-Zero can occur. This approach only makes sense for generating stimuli vectors for structural test goals.
Complete

The second approach is called Model Checking. Please note, that this method should not be confused with a guideline checker in an environment like Simulink. Model Checking originated in the early 1980s was originally invented by two research groups in the United States (Clark, Emmerson, McMillan) and France (Quielle/Sifakis). Model Checking is an efficient search procedure for finite state machines to determine whether they fulfill a specification expressed in temporal logic. To optimize this approach symbolic model checking or reduced ordered binary decision diagrams have been introduced.
A model checker performs a complete analysis of the behavior of a system against a specific static or temporal property and proves if this property holds or if it can be violated. In the case of a violation, a counter example is provided that enables the user to debug the violation. Complete analysis means that all possible runs of a system will be analyzed within one analysis task and deliver complete mathematical proof of the results.
To generate stimulus vectors or test cases with this method, the Model Checker provides a counter example when a supposedly unreachable test goal can be covered. This approach can be used for all test goals mentioned before.
Use cases for automatic test case generation
Now that we have established our test goals and which methods we will use, and we explored options for generating test data, we can now take a look at the use cases where the test data can be used.
When to use structural stimuli vectors?
Back-to-Back Testing
One of the most prominent use cases for structural vectors is Back-to-Back Testing, which is also highly recommended by ISO 26262. This test compares the behavior between two implementations of the software. Most often this is a comparison between model and code to check if the model is correctly translated into code. This can be exceptionally helpful if the model uses floating-point and the code uses fixed-point. But even if both implementations use floating-point, there might be differences if the model calculates in a 64-bit environment, while the code calculates in a 32-bit. Have look at the blog article What you should know about floating-point for additional information. Furthermore, differences can occur when different compilers are used.
Regression and Migration Tests
Additional use cases are, for instance, Regression Testing, which compares an older version of a model or code to a newer version. If the target processor changes, this approach can be used to compare the behavior between the older and newer hardware. Additionally, you can also perform a Migration Test to secure a version change of your development environment if you are going to use newer Matlab and TargetLink versions.
Approach
The basic approach is to get the highest possible coverage on a model or the code. Therefore, already existing test cases can be reused or you can perform the automatic test case generation to get the stimuli vectors needed to cover all test goals. Regardless of the data source, only input data provided is used for this type of test. We ignore any output data provided, because the outputs from our test data is used in the actual analysis.
These stimuli test data are then simulated on the reference implementation in the first step and the resulting output data is recorded. Together with the input data, this produces an execution record. In the second step, the exact same stimuli test data is executed on the implementation to be compared and the output data is also recorded. In the third step, the execution records of the two implementations are then compared with each other to see if there are any differences. Tolerances can be defined in the case that we need to accept small deviations (e.g. caused by a floating-point model and fixed-point code.)
When to use robustness stimuli vectors and “unreachables”?
The usage of robustness stimuli vectors and unreachable results are obvious for this use case. A software unit can be considered to be robust, if the robustness test goals that should be unreachable are actually proven to be unreachable. Proven robustness test goals should not lead to runtime errors or undesired behavior. For example, if we know our floating point code has a Division-by-Zero condition potentially leading to an Inf/NaN, then we can take steps to handle it. Also, a cast to a smaller data type (Downcast) can be accepted, if the source value will always fit into the target datatype range or the overflow / underflow is intentionally used (e.g. compute through overflow).
When to use Drive-to-State stimuli vectors and unreachables?
Stimuli vectors or corresponding unreachable results for drive-to-state test goals are used to prove that a certain critical state, e.g. that two mutual signals must not be active at the same time, cannot occur in the system. In addition, they can be used to find out whether or not certain niche-situations (especially error handling scenarios) can occur.
When to use requirements-based test cases?
This use case is actually self-explanatory, as long as the requirements have been translated into a machine-readable format in advance. The generated test cases can replace the manual writing of requirement-based test cases. They prove that a requirement can be fulfilled and can also be used for back-to-back and regression testing. However, these test cases do not prove that a requirement cannot also be violated.
It is also important to note that this use case can be time consuming, since the requirements must first be made machine-readable. However, it presents new opportunities as we can also use the formal requirements for other use cases such as Formal Test or Formal Verification.
Conclusion
If we revisit the initial question about whether automatically generated test cases are useful or if they offer no added value at all, we come to the clear conclusion that automatic test case generation can be beneficial in many ways. However, it is essential to understand which type of test data is best suited for a given use case. The following table provides a final overview of the test goals and data, the methods used to generate the test data and the appropriate use cases.